Webサービス「クイズ・グランQ~AIソムリエのワインドリル」の技術トピックス
本投稿は Webサービス「クイズ・グランQ~AIソムリエのワインドリル」の開発・実装に関する技術トピックスです。
弊所の備忘録ではありますが、類似のサービスの開発を検討される場合にご参考下さい。
また、ご相談も受け付けております。(contact@esslab.co.jp)
はじめに
クイズ・グランQ は3択のワイン関連クイズを楽しむWebアプリケーションです。
アプリURL:https://winedrill.web.app
ワイン検定レベルのワイン関連知識を、あたかもドリルをこなすように少しずつ問題を変えながら繰り返せる仕組みを作りたかったのが発端です。
巷には電子書籍の問題集なども出回っていますが、実際にやってみると、離れたページにある答え合わせをするのが面倒くさいし、コンプリートしていく過程が可視化できずに不便です。アプリ化すれば進捗・正解率が即座にわかり、間違えた問題だけ繰り返しやってみる、重要マークを付けた問題だけ繰り返す、など簡単に出来ます。それなら僅かな空き時間など暇つぶしを兼ねて遊びながら覚えられてしまいます。
仕様面については弊所のリリースとアプリ自身のガイド画面をご覧頂くことにして、ここでは割愛致します。
リリース:https://esslab.co.jp/products/winedrill
ガイド画面:https://winedrill.web.app/start
サービスの骨子は以下のようなものです。
- フロントエンドは汎用的な3択クイズのWebアプリケーションにする
- バックエンドのコンテンツデータをワイン関連のクイズに特化する
- 数十問で1つのタイトルとし生成AIを用いて毎週新しいタイトルを追加していく
- ときどきワイン以外の話題(号外)や人手で編集した「特別編」タイトルも投入する
- 利用登録(無料)によりユーザー毎に進捗の保存が可能になるが、未登録でも制限つきで試せるサンプルモードを用意する
- クイズテーマに紐づくアフィリエイト広告をクイズ画面の下部に表示する
今回の技術トピックスでは、全体概要を示したあと、上記 3.生成AIによるクイズ作りの課題にフォーカスして記載します。
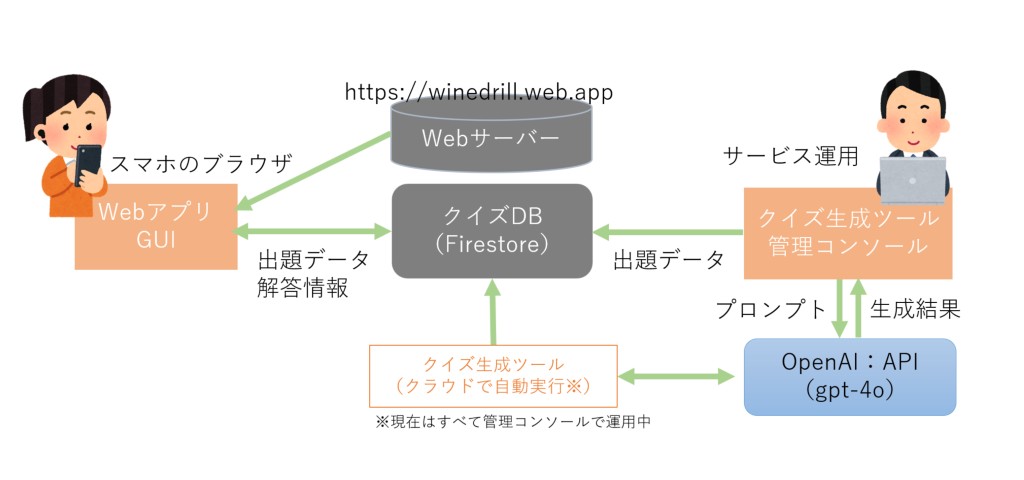
1.全体概要
- クイズのGUIを提供するWebアプリケーションは REACT/JavaScriptで GCPでhostingしています。
- クイズデータは Google Firebase に保存し、Webアプリがこれを読みだしてクイズを提供します。
- クイズデータの生成はデスクトップでツール※を走らせてタイトル単位で作成し、これをFirebaseへ送信して蓄積します。
- 利用登録したユーザーの解答記録は Firebase に保存することでクイズの中断/再開を可能にしています。
※使用しているAIは OpenAI社 gpt-4o(2024.12時点)です。
2.AI活用のポイント
タイトル1つあたり数十問のクイズデータを継続的に作り続けるのは、限られた人手では到底無理です。
このサービスの開発検討時点では既にOpenAIをはじめとする優れたAI機能のAPIが提供されて1年以上経っており、手触り感もありましたのでクイズデータは生成AIで作る、という方針になります。
まず実現可能性を検証してからサービスの実装に着手することになります。
(1)生成AIにクイズは作れるのか?
(2)望みの難易度や切り口にできるのか?
(3)出題の妥当性チェックはどうするのか?
(4)どうやってバリエーションを制御するか?
検証の過程で、当初思っていたのと仕様・運用を変えざるを得なくなったところもありました。
以下、これらの課題を説明します。
2.1 生成AIにクイズを作らせる
(1)最低限のライン ⇒ 作れる
これはChatGPTのような対話型UIからでもすぐ試すことができます。
例えば「フランスのボルドーワインに関するクイズを20問作って」のような簡単なプロンプトでも、AIが自分の学習済み知識をもとにクイズ形式の文章を生成できることが分かります。三択なので正解以外の選択肢もそれらしい言葉を並べてくれます。
(2)データの安定性 ⇒ 作れる
上記ではAIが出してきた文面を人間が読むので問題と選択肢を理解できますが、ユーザーに問題と選択肢を表示するGUIのアプリが読み込むためには、プログラムが読みやすいデータに変換する必要があります。
幸い、OpenAI のAPIには JSON出力を指定するができますので、曖昧性のある長文をプログラム用のデータフォーマットに変換するプログラムは不要で、作成したクイズをいきなりJSONで出させることによって、安定的に決まったフォーマットのデータが得られます。
APIに渡す role.system の記述文の中で「JSONで出力すること」を指示し、APIの引数でも
response_format = { "type": "json_object" }を指定します。ちなみに、JSONを指示しない場合はこの項目自体を指定しません(デフォルトがテキスト)が、JSON指定するしないをコードで条件分岐する場合にテキストを明示したい時は下記のようになります。
response_format = { "type": "text" }
(3)採用した方法複数パターンをテストした結果、毎回異なるクイズ作成指示が入る role.user の文章ではなく、共通して用いる role.system の文章の方に具体的なJSONのサンプルを記述することで安定した出力を得ました。(数千問以上の問題作成を行ってフォーマットに合わないデータは生成されませんでした)
但しこれを作った後で、gpt-4o-2024-08-06 から明示的にスキーマを指定する方法がサポートされたため、今後はそれを使うのが望ましいです。
response_format = { "type": "json_schema" , "json_schema":"・・・"}
2.2 望みの難易度や切り口にする
(1)カバー範囲 ⇒ ある程度可
クイズの内容を問わなければ上記の最低限のラインでOKですが、さすがにそうもいきません。
20問でどういう範囲をカバーし、どの程度の詳細度(難しさ)で出題して欲しいかをコントロールする必要があります。
そのため、プロンプト内で、出題してほしい観点を記述しています。
「フランスのシャンパーニュ地方とロワール地方のワインに関するクイズを…(中略)…
・シャンパーニュ地方の歴史、気候風土、地方料理に関する問題
・シャンパーニュの品種やタイプ、生産形態や醸造方法、ワイン法に関する問題
・ロワール地方の歴史や気候風土、地方料理、産地の主要地区のワインに関する問題 …」
観点の記述はその出題対象に応じて変わってしまう(例えばシャンパーニュでは製法に関する設問が必須だがそれが不要な産地もある等)ので、プロンプト作成者は出題対象の知識が要ります。その知識も含めてAIに入れるプロンプトをAIに考えさせる多段階生成を探求する可能性は残るとしても、どの段階かにどうしても人間の「意図」を込めざるを得ないでしょう。
ひとまず、技術面ではプロンプトで観点を指定すればよいこと、何を書くかはコンテンツ作成者次第としておきます。
(2)難易度 ⇒ 可、但し副作用あり
例えばボルドーやブルゴーニュなどの超有名生産地に関するクイズをAIの学習済み知識から引き出すと、どうしても良く知られた事項が繰り返し出題され(簡単すぎ)たり、逆に情報量が多くて難し過ぎる問題が出たりと、カバー範囲の指定だけでは難易度を調整することができません。
そのため、知識生成プロンプティング を併用します。
カバー範囲の指定など一通りの指示を書いたうえで「なお出題内容については以下の知識も活用して・・・」のように出題に含めてほしい具体的なファクトをプロンプトの最後に添付します(したがって長文のインプットになります)。
当初ワインドリルの作成に当たっては(一社)日本ソムリエ協会のワイン検定レベルを想定しましたが、重視ポイントなどの意図を汲まないとレベルを合わせようがありませんので、検定テキストを読んで要点をまとめて入力しています。
なお、検証開始時は gpt-4, gpt-4-turbo でトークン数の上限が気になりましたが、gpt-4o からほぼ気にする必要がなくなり、入力も出力(つまり作ったクイズの文章)にも十分な自由度が持てるようになりました。
2.3 出題の妥当性チェックを行う
生成AIでそれらしい問題が20問作成できるようになったとして、妥当性チェックが必要になります。
人手で全ての問題のファクトチェックをするのは無理なのでここもAIを使います。
一旦出力された問題と解答・選択肢のデータは自動的にプログラムでリフォームして再度AIに入力し検証作業をさせます。
- 問題文が曖昧すぎたり無理な質問をしていないか
- 正解としている選択肢が本当に正しいか
この検証作業で問題があれば①指摘の文章を、問題がなければ正解とされる事実に対する②簡単な解説文を、JSONで出力させ、①がある場合は警告を出して人がチェック&修正するフローへ、②はユーザーが選択肢を押して正誤判定をしたあとに画面に表示する情報としてクイズデータに組み込みます。
ファクトチェックで見つかる齟齬の1つに統計データの問題があります。例えば世界のワインの生産量の順位や特定地域で品種が何パーセントを占めるかなど、いつの段階での統計かによって答えが変わるものがあり、出題意図を踏まえて人手で「正解」を設定します。
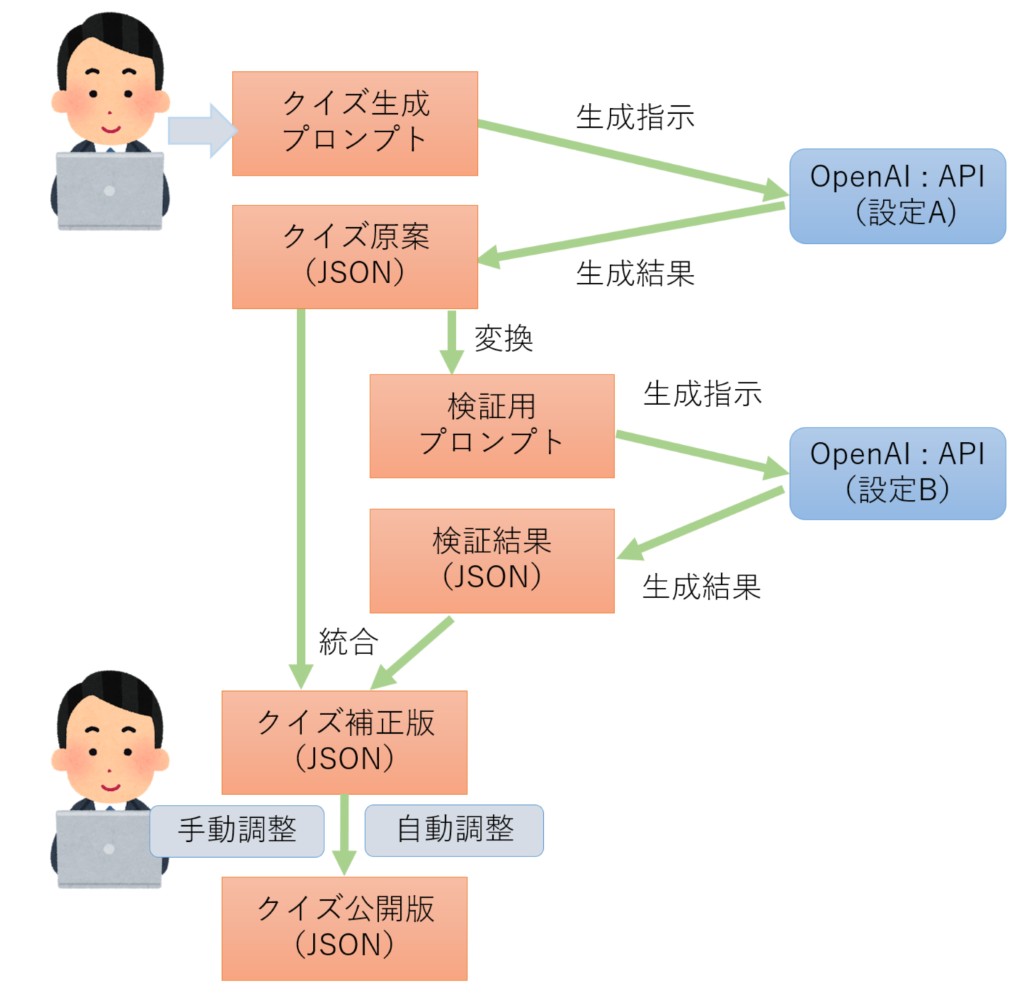
指摘のあった問題をAIに修正させるループも試しましたが、問題を直すのか、選択肢を直すのか、元の出題意図(この情報はない)を教えずに自動修正を試みても満足のいく結果になりません。修正が困難な場合はその設問自体を出題データから削除するように指示すると、殆んどの場合、AIは削除を選択してしまいました。
統計データの問題のように正解が一意に決まらない場合もあるため、結局、人手の確認・修正フローを入れた運用となった経緯です。実は当初案では、クラウド上で毎週自動でクイズ生成を行い(自動検証・自動修正も行い)、コンテンツが追加されていく仕掛けにしたかったのですが、これらの状況から「完全自動運転」は現状では無理と判断しました。
結果、クイズ生成はデスクトップのツールで行った後コンテンツサーバーへ送る運用をしています。
2.4 バリエーションを制御する
あたかも人間が編集したかのような程よいバラツキと重複を伴う似て非なる問題集を量産したい。
例えばドイツ・ワインの20問をドリルしたあと、次にドイツ・ワインの新しい20問が追加される場合、理想は、一部の頻出問題だけ重複しつつ新しい問題がでることです。なぜなら同じ人がやり続ける場合は問題はなるべく入れ替わって欲しい反面、新しい20問からこのアプリを始めた人には頻出問題も必要だからです。一方で条件一定のままクイズ生成を繰り返せばAIは毎回同じような問題ばかり作成してしまいバリエーションの観点からはどちらも満たすことができません。
- 過去何回分かの問題をすべてプロンプトで教えた上で次の20問を精度良く作らせる
- 大量の問題を一度に作らせてプログラムが適度なシャッフルで20問ずつ切り出す
このバリエーションの生成は思ったより難しい課題で、上手に解決しきれていません。
今の段階ではある程度予測可能なアウトプットが得られる後者の方法を採用しています。他にも実際に運用を初めてクイズの量産を始めると、手がかかる部分があります。
たとえば、学習済みの情報自体があまり潤沢でないと思われる地域を出題すると、知識生成プロンプティングで与える情報に過度に頼ってしまうようで、与える情報の範囲内でほとんど同じ問題ばかり生成する現象があります。出題の生成数の指示を増やすことで多くの知識から出題を引き出せる場合もありますが、数を増やすと同じ問題を重複して生成してくるようになったりと、お題によっては人手で調整・工夫が必要になっています。
また、三択の選択肢では正解番号をランダム化するよう指示していても、お題によっては1つめの選択肢に正解が集中しすぎる現象があり、後処理プログラムで偏りを判定して選択肢を自動シャッフルするなど、クイズ生成システムとしては小細工がいろいろ必要なところがあります。
gptのモデルが更新されると挙動も変わりますし、同じプロンプトでも同じ結果が出ないことが好都合でクイズのバリエーションを作成できる反面、期待する動作から大きく外れていないか、人手による最低限のチェックは外せない現状です。
バリエーションの自動化はまだまだ改善の余地がある課題です。
3.今後に向けて
以上を簡単に総括すると
- 生成AIを使って定型フォーマットでクイズのデータを作成できる。
- プロンプトの指示文や知識生成プロンプティングを組み合わせて難易度や切り口をコントロールできる。
- AIによる事実確認や修正も可能だが、現段階では人間によるチェックを完全には排除できない。
- ソフトを工夫すれば同一テーマを繰り返してバリエーションを作り出せる。
今回の実装を経て今後考えるべき点が2つあろうかと思います。
(1)クイズグランQの自動化推進
当初考えていたようにスケジューラーがクラウド上で毎週クイズ生成プロセスを実行してコンテンツを継続的に追加する形態を目指す(人手をかけなくて運用できるようにする)。
AI技術は変化が激しく四半期ごとに性能が上がってコストが下がっています。現状の技術に合わせて様々な最適化を行っても、ゲームチェンジしてしまう(=AIが賢くなって余計な工夫が要らなくなる)可能性も大きいです。下記と併せて現行のシステムで運用しながらより簡単で汎用的な方法を探ります。
(2)フレームワークの汎用化
今回課題となった点はいずれも「クイズ」の生成に特殊な話ではなく、多くのタイプのコンテンツ生成に対して共通している事でもあります。
何らかのお題となるコンテンツ生成にAIを活用するには以下4つの課題がついてまわるはずです。
- 生成AIの適性を判断する方法
- 期待する方向に誘導する方法
- 生成物を検証して自己修正させる方法
- 繰り返し生成に対してコンテキストを持たせる方法
引き続きクイズグランQ運用を通してより汎用的な手法を探索していきます。
ー 以上 -
